自动规则合规性检查要求从规范文本文档中自动提取需求, 并且形式化为计算机可处理的规则表示形式. 这样的信息提取(IE)是一个具有挑战性的任务, 需要进行复杂的分析和文本处理. 自然语言处理(NLP)的目的是使计算机以人类的方式处理自然语言文本. 本文提出了一种基于语义, 规则的NLP方法, 用于从建筑法规文件中自动提取信息. 所提出的方法在IE中采用基于模式匹配的信息抽取规则(IE rules)和冲突消解规则(CR rules). 各种各样的语法和语义文本特征被用在IE rules和CR rules的模式中. 提出了基于短语结构语法(PSG)的短语标记和语义信息元素的分离和排序, 用来减少所需模式的数量. 本体论被用来帮助识别语义文本特征(概念和关系). 所提出的IE算法被用来测试2009 International Building Code中的定量需求规则, 分别达到了0.969和0.944的精确度与回调率.
Introduction
第一段: 举例论述了工程建设项目受到大量联邦, 州以及地方的规则管治, 而且每个规则有大量的条文.
第二段: 强调建筑规范是建筑结构设计, 建造, 变更和维护的主要法规, 被广泛采纳和使用, 甚至被修改后用来适应地方性的要求. 这样一来, 有大量的建筑规范存在, 每种规范都有自己的形式和语义结构. 而且在同一个规范中, 这一章和另外一章的条款形式和语义可以是不一样的.
第三段: 考虑到建筑规范文件的庞大数量, 条款的格式和语义的变化以及描述内容的繁杂, 导致人力进行规范的合规性检查是耗时, 成本高而且易出错的——举了两个实例说明. 自动化规范检查的目的就是减少时间和成本以及错误率, 随着计算机技术的发展, 许多研究工作都在推动自动合规性检查——展开前人的工作(Solibri Model Checker, EPLAN/BIM led by FIATECH, CORENET led by the Singapore Ministry of National Development, REScheck and COMcheck led by the U.S. Department of Energy, SMARTcodes led by the International Code Council, Avolve Software.)毫无疑问, 前人的工作为ACC铺平了道路, 但是他们的工作受限于自动化和推理能力. 现存的ACC系统需要人力去提取规范文本中的需求并且把他们编码成计算机能处理的格式. 规则要么被硬编码进入开发的系统, 要么被手工编码成为规则数据库或者文件集. 举例说明了该问题.
第四段: 为了解决这个问题, 作者提出了一种新的规则信息自动提取方法用于支持ACC.
Proposed Approach for Automated Regulatory Information Extraction
NLP Approach
一种用于从建筑规范文档中自动提取信息的基于语义和规则的NLP方法被提出. 作者的分析表明领域特定规范文本与普通非技术文本相比更加适合自动化NLP. 原因一: 建筑文本与非技术本文相比有更少的异义词;原因二: 开发特定领域的本体论比与开发一般领域的本体论要容易. 原因三: 规范文本有更少的代指问题.
Rule-Based Approach
提出的方法是基于规则的. NLP有两类主要的类型: 一种是基于规则, 另外一种是基于机器学习. 基于规则的方法手工编写规则用于文本处理, 迭代构造和改进这些规则以提高文本处理的准确率. 基于机器学习的方法基于给定训练文本的特征使用机器学习算法去训练文本处理模型. 基于规则的NLP往往表现出更好的文本处理能力但是需要更大的人力. 在本研究中采纳基于规则的方法因为它有更好的性能. 所提出的方法使用依赖于模式匹配的IE rule, 根据已经识别过的文本产生模式来提取需要识别的文本. 这个方法依赖于文本的语法和语义特征来定义这些模式. 文本的语法特征的捕获是使用各种各样的NLP技术, 包括tokenization, sentence splitting, morphological analysis, POS tagging, phrase structure analysis. 文本的语法特征(概念和关系)的捕获是基于表现领域知识的本体论. 考虑到文本的组成和递归性质, 句子可能冗长而且复杂, 这就导致了有大量的模式. 所提出的方法在语法分析中使用短语结构语法(phrase structure grammar, PSG)来减少IE规则中需要的模式. 减少模式的数量可以使IE rule更加泛化, 也增强了提取能力, 实现更少的IE rule来进行提取和减少开发规则所需要的人力. 提出的方法还使不同语法信息元素分离和序列化进一步的限制了IE rule的数量. 除了IE rule外, 还使用了一组解决冲突的信息提取规则(CR rule).
Semantic Approach
使用领域本体论获取语义特征. 本体论以概念层次, 关系(概念之间)和公理的形式模拟领域知识. 基于本体论的语义IE与基于语法的IE相比可以达到更好的性能因为领域知识可以帮助辨识或区分领域特定术语与意义.
Comparison to State of the Art
现有的语义IE研究主要有四个方面: 命名实体抽取, 属性抽取, 关系抽取和事件抽取. 命名实体抽取, 属性抽取, 关系抽取的目的是提取单个或两个相关的概念的实例. 事件抽取的目的是抽取多个概念的实例. 从这个角度看, 所提出的方法更加接近于事件提取因为需求条款中有多个概念的实例被提取. 然而, 与事件提取相比, 这个方法也有不同, 主要表现在两个方面: 第一, 提取信息的方式更加灵活. 在提出的方法中定义了两类语义信息元素: “刚性信息元素(rigid information elements)”和”柔性信息元素(flexible information elements)”. 一个刚性信息元素拥有一个预先定义的, 固定数量的概念或关系. 相反的, 柔性信息元素根据手头上的实例具有不固定数量的概念或者关系. 与事件抽取不同的是, 所提出的方法可以提取柔性信息元素的实例. 其次, 引入了一种以更灵活的方式提取信息元素的方法, 执行更深层次的信息提取. Shallow NLP进行语句部分分析或者从一个特定的角度对句子进行分析. Deep NLP的目的是对句子进行全面的分析, 理解句子意义. 相应地, Shallow IE从句子中提取特定类型的信息, 而Deep IE旨在基于句子的完整分析提取句子所表达的所有信息.
从IE的表现性能来看, 对于四种不同的信息(实体, 属性, 关系和事件), 目前的表现精确率和回调率结果都在0.80-0.90的范围内. 最近的一个针对提取受保护的健康信息的研究报告其精确率和回调率分别为0.9668和0.9377.
该段主要论述了NLP技术在建筑领域的应用, 提出了前人的不足之处, 说明与前人相比, 本研究的区别主要在以下几个方面: 1.解决了一个不同的应用问题(即ACC). NLP 方法, 算法和结果都是高度依赖于应用场景的. 2.解决了一个更深层次的NLP/IE任务. 作者的目的是自动处理文本从而提取规范需求或者规则, 并且将他们表示为逻辑句子. 3.使用了一个更深的语义方法用于NLP. 作者使用一个领域本体论用于识别文本语法特征. 使用领域特定语义和”柔性信息元素”去实现相对深层次的NLP.
Background—Phrase Structure Grammar
主要介绍了短语文法——0型文法和上下文无关文法….没什么好说…
Proposed Information Extraction Methodology
简要叙述了IE方法, 将该方法分为七个阶段, 迭代提高性能.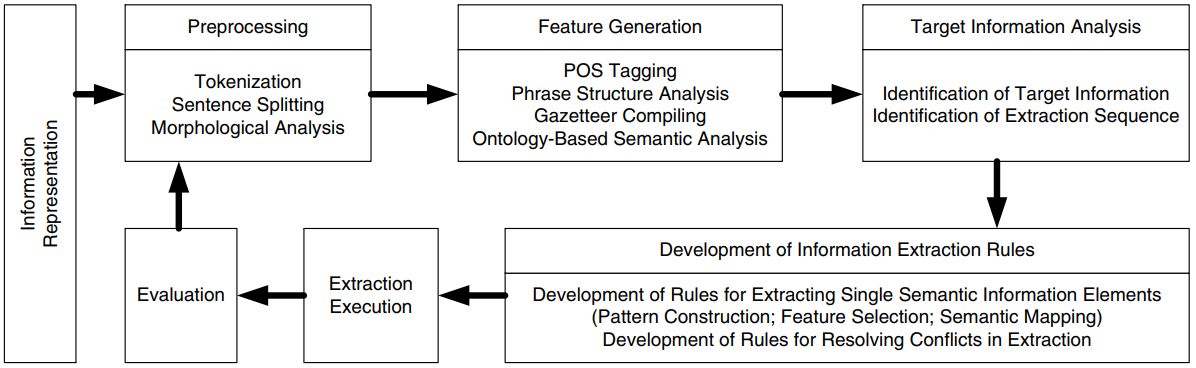
Phase I—Information Representation
方法中提取信息的最终表示形式是一个或更多个可以直接用于自动合规性检查推理的逻辑句子. 为了中间处理, 提出一个新的ACC元组的概念, 用于表示提取的信息. 以元组的形式表示易于计算机的操纵和评价.
在ACC元组的表示中, 每一个元素都被称为一个”语义信息元素”(simple semantic information element, SIE), 它是(1)一个本体概念(2)一个本体关系(3)一个义务操作符指示器(deontic operator indicator)(4)一种约束关系(restriction). 由此又产生以下几种类型的语义信息元素: 简单语义信息元素(simple SIE)对于复杂语义信息元素(complex SIE), 刚性语义信息元素(rigid SIE)对于柔性语义信息元素(flexible SIE).
为了进一步将信息转换成逻辑句子, 使用语义映射步骤将提取的信息元素实例与其各自的语义概念相匹配: (1)对于本体概念或关系, 它们的信息元素实例被映射到对应的概念和关系上. 例如”courts”映射到”court”, “net area”映射到”net_area”, “not less than”映射到”greater_than_or_equal”;(2)对于义务操作符指示器, 它们的实例会被映射成为指示义务概念(indicated deontic concepts);例如”shall”会被映射到”obligation”;(3)对于约束关系, 它们的实例将被分解, 映射到一个或多个本体概念或关系上. 例如, “between the insulation and the roof sheathing”会被映射到”relation(between, insulation, roof_sheathing)”.
提取出来的信息元素实例(以ACC元组的形式), 在进行必要的语义映射后将会进一步转化为霍尔子句类型(Horn-Clause-type)的逻辑句子, 用于合规性检查的逻辑演绎和推导.
Phase II—Information Representation
Tokenization
分词, 没啥好说.
Sentence Splitting
分句, 没啥好说.
Morphological Analysis
形态分析, 没啥好说.
Dehyphenation
消除上下两句话之间的连字符, 没啥好说.
Phase III—Feature Generation
这个阶段产生一组用于表述文本的特征. 语法标签(POS tags, PSG-based phrasal tags, gazetter terms), 语义标签(概念和关系). 随后这些标签将被用于定义模式.
Part-of-Speech Tagging
词性标记, 没啥好说.
Phrase Structure Analysis
根据POS tagging的结果将词性标签进行归纳. 例如”Habitable rooms,” “shall have a net floor area of not less than 70 ft2,” and “of not less than 70 ft2” 分别被标记为NP, VP, PP. 在所提出的方法中, PSG被用于产生短语标签. 在这个方法中, 领域特定的PSG规则基于随机选取的文本样本产生. 应用PSG规则后, 当特定的POS标签组合产生后, 就会被归纳称为短语标签. 短语标签和PSG的结合减少了模式的枚举数量.
做了一个关于使用基于PSG的和不使用PSG的抽取主语的实验, 使用PSG需要22种模式, 不使用的话需要46种模式.
Gazetteer Compiling
Gazetteer是一组包含特定实体名称的列表. Gazetteer中的某个词或短语会被用作IE任务中的特征.
Ontology-Based Semantic Analysis
论述本体论提供了语义表示. 做了一个实验证明有语义比没有语义表示的IE要好.
Phase IV—Target Information Analysis
这个阶段主要是人工分析文本, 确定提取的语义信息元素的类型和他们的关系, 以及提取它们的顺序.
Identification of Target Information
这个步骤, 待开发的文本将被人工分析以确定文本中描述的需求类型(比如, 数量需求类型). 根据领域知识(表示在本体论中), 定义表示需求类型所需要的语义信息元素类型. 例如, 如果被提取的信息跟恐怖袭击事件相关, 那么语义信息元素的类型可能包括”恐怖分子”, “恐怖组织”, “目标”, “受害人”和”武器”. 例如图中, 被提取的信息与数量需求相关, 因此作者定义了以下几种类型的语义信息元素”subject”,”compliance checking attribute”,”deontic operator indicator”,”quantitative relation”,”comparative relation”,”quantity value”,”quantity unit”,”quantity reference”,”subject restriction”,”quantity restriction”.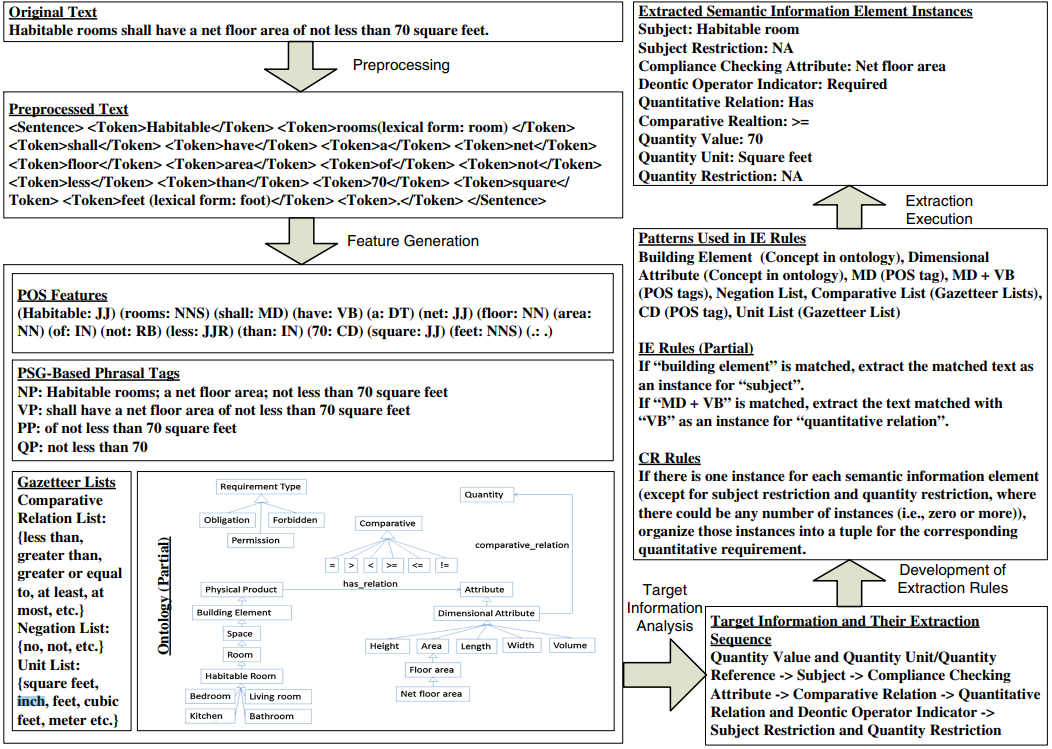
Identification of Extraction Sequence
这个步骤主要确定提取语义信息元素的顺序. 如果使用单一的IE rule提取所有的语义信息元素是不高效的, 因为可能的模式会随着语义信息元素的增加而大量增加. 由于信息元素中的独立性(并非完全独立), 提出了分离和顺序提取信息元素的方法. 基于对文本的人工分析和识别决定不同语义信息元素的提取顺序: (1)提取的难度等级. 最简单的应该首先被提取出来, 这个难度等级与组合特征的数量, 模式的数量和模式的复杂程度呈正相关. (2)提取的不同语义信息元素间的现存依赖性. 例如, 如果”quantity value”只需要POS tag”CD”作为辨识基数的特征而且其提取难度最低, 那么它应该首先被提出. 再例如, 如果”subject restriction”的提取依赖于”subject”的提取, 那么”subject”应该比”subject restriction”先提取. 图中的语义信息元素提取的顺序为”quantity value” and “quantity unit/quantity reference” > “subject” > “compliance checking attribute” > “comparative relation” >”quantitative relation” and “deontic operator indicator” > “subject restriction” and “quantity restriction.”
实验验证separation and sequencing of semantic information elements (SSSIE).
Phase V—Development of Information Extraction Rules
开发了一组规则去自动化执行信息提取处理. 所提出的方法包括使用和开发两种类型的规则: 抽取单个语义信息元素的规则(IE rules)和解决抽取冲突的规则(CR rules). IE rules识别提取的目标信息, 而CR rules定义了在提取中处理冲突的策略.
Development of Rules for Extracting Single Semantic Information Elements (IE Rules)
提取的规则(IE rules)使用模式匹配的方法. 规则的左边定义了待被匹配的模式, 右边定义了要提取的部分. 文本的语法和语义特征都被用于IE rules模式中. 如果本体论中的某一个概念被用于某一IE rule, 那么它的所有子概念也被包括在匹配中. 例如, 在下面的IE rule中, “building element”是本体论中的一个概念: “If “building element” is matched, extract the matched text as an instance for”subject”.”在图中, 这条规则就抽取”habitable rooms”作为”subject”的实例, 因为”habitable room”匹配”Habitable_Room”(本体论中”building element”的子概念).
为了开发这些IE rule, 提出以下三个任务: 模式构造, 特征选择, 语义映射. 对于模式构造, 这些模式采用特征组合的顺序格式(例如”NP VP”匹配一句话). 这样的模式构造过程是一个迭代, 经验的过程. 特征选择旨在选择构造模式中的所有特征. 在语义映射中, 被提取的语义信息实例会被映射到对应的语义上. 例如图中, 模式”MD VB”被构造用来提取”quantitative relation”, POS tags被选择作为特征, “shall have”匹配这个模式, “have”被语义映射到”has”.
Development of Rules for Resolving Conflicts in Extraction (CR Rules)
主要解决四类冲突的情况: (1)在单句语句中的信息元素实例的数量大于需求;(2)在单句语句中的信息元素实例的数量小于需求;(3)不同语义信息元素的提取结果存在重叠;(4)无冲突;
Phase VI—Extraction Execution
这个阶段旨在采用PhaseV中所提出的规则从规范文本中提取目标信息元素实例. 例如图中, “habitable room”和”net floor area”分别被提取作为”subject”和”compliance checking attribute”的实例.
Phase VII—Evaluation
将提取信息与”黄金标准”比较进行评价. 这个”黄金标准”包括规范文本目标信息的所有实例而且被领域专家人工(或者在NLP工具下半自动)编辑. 使用以下三种指标进行评价: precision, recall, F-measure.
Validation: Experiments and Results
Source Text Selection (International Building Code)
使用IBC2006(ICC 2006)和IBC(2009), IBC2006的12和23章被随机选择用于开发, IBC的19章被用于随机选择做测试. 定义了IBC中条款需求两个主要类型: 一个是定量条款(quantitative requirement), 另外一个是存在条款(existential requirement). 选择用定量条款做实验是因为: 这些章节的大部分条款都是定量条款, 而且描述定量需求的条款比描述存在需求的条款更加复杂, 也就是说更难提取.
Ontology Development
开发了一种面向应用和领域特定的本体论. 在构建本体论的过程中, 现存的建筑本体论(例如再次利用了IC-PRO-Onto和IFC的概念). 本体论被写为OWL格式.
Information Representation
提出九元组用于中间信息表示: 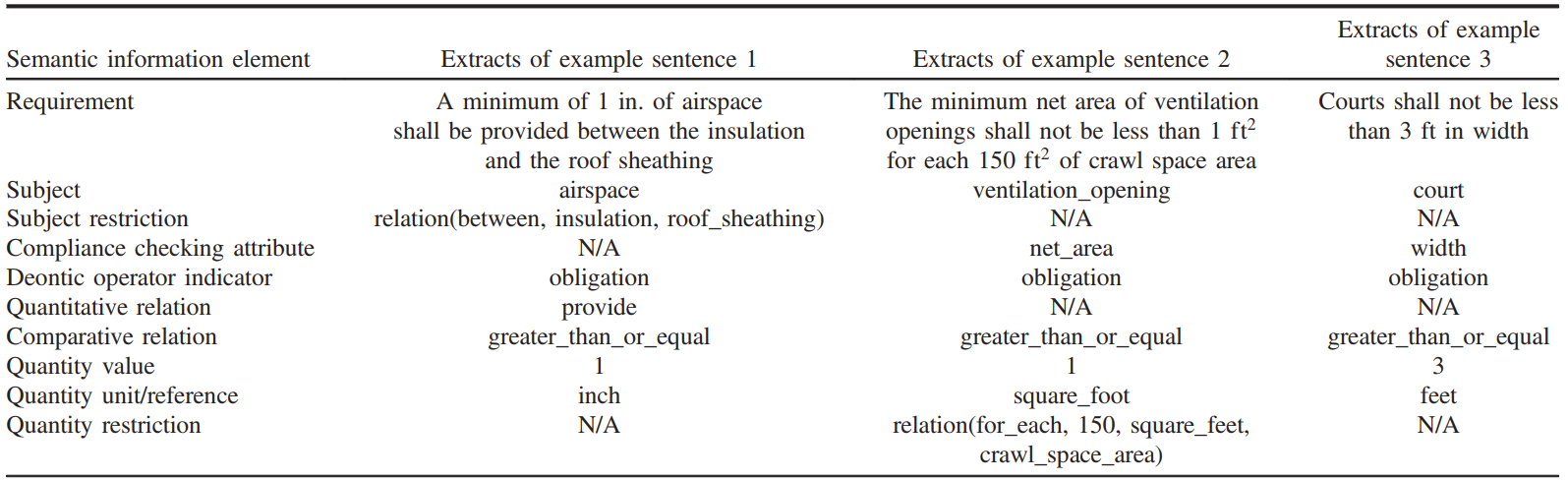
Development of Gold Standard
黄金标准是半自动化开发出来的, 首先, 所有包含数字的句子(用数字表示或者单词标识的数字的句子, 以保证描述定量条款的句子的100%回调)都被自动提取出来;接着作者手动删除错误的句子然后将每个句子的语义信息元素的实例. 在IBC 2006的12, 13章, 304条包含定量条款的句子被识别, 形式化成黄金标准.
Tool Selection (GATE)
今天有许多现成的工具可以用来支持各种各样的NLP任务包括信息提取, 这样的工具包括由斯坦福NLP团队开发的Stanford Parser和谢菲尔德大学开发的GATE. 选择使用GATE实现这个IE算法是因为(1)GATE已经在IE中被广泛成功应用(2)它以插件的方式嵌入了许多其他NLP工具, 例如Stanford Parser和OpenNLP工具. 在实验中以下几个GATE的内置工具被使用: (1)ANNIE被用来tokenization, sentence splitting, POS tagging, and gazetteer compiling;(2)内置的morphological analyzer用于形态分析;(3)内置的本体论编辑器用于本体论的构建和编辑(4)JAPE用于写IE和CR规则.
Applying the IE Methodology
使用GATE将上述方法实现。
